【Python3】SeleniumでWebページをPDFにして自動ダウンロードする方法
おはこんばんにちは、せなです。
今回はSeleniumを使用して特定のWebページをPDFにして自動ダウンロードする方法を解説したいと思います。
コード
説明は後述しますので、まずは下記のソースコードをご覧ください。
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
# オプション設定
options = webdriver.ChromeOptions()
options.add_experimental_option('prefs', {
'download.default_directory': '~/Downloads'
})
options.add_argument('--kiosk-printing')
# ドライバ起動
driver = webdriver.Chrome(ChromeDriverManager().install(), options=options)
driver.get('https://www.google.com/')
# 印刷画面の表示
driver.execute_script('window.print();')add_experimental_option はchromeにオプションを追加します。'prefs', {'download.default_directory': '~/Downloads'} はデフォルトのダウンロード先を設定するオプションとなります。
add_argument も同様にChromeにオプションを追加します。'--kiosk-printing' はキオスクモードでこちらを追加すると、印刷画面を開いた際に自動で印刷ボタンを押下してくれるようになります。(ユーザーに印刷画面の操作を行わせないようにするためのオプションみたいですね。
最後にgetでURLを呼び出してexecute_script('window.print();')で印刷画面を表示してPDFダウンロードしています。
上を実行するとこんな感じのPDFがダウンロードされますね。
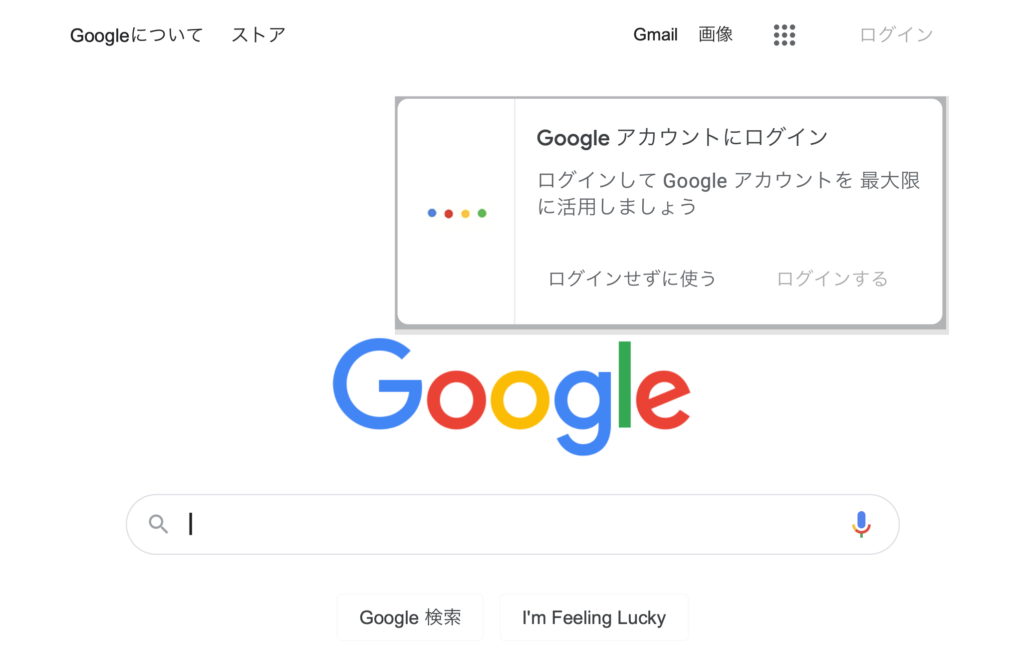
ちなみにwebdriver_managerはChromeバージョンを自動で合わせてくれる便利なライブラリです。
以下で解説していますので、よければ参考にしてください。
SeleniumでChromeとChromedriverのバージョンを自動で揃える方法
最後に
ここまでご覧いただきありがとうございます。
作業中に困ったことなんかを記事にしていますので、よければ他の記事もご覧ください。
ではでは〜